

定性AI
行为或表现是特定的,而且可以预测的,没有不确定性。具体实例可以是简单的追逐算法。比如说塑造一个怪物角色,沿着 XY 坐标轴前进,往某目标点移动,直到该角色的 XY 坐标和目标点的坐标重叠。
非定性AI
某种程度的不确定性,有点不可预测(不确定到什么程度与人们对所采用的的 AI 的方法的理解的难易程度有关)。具体实例是让非玩家角色学习到适应玩家的作战战术。这样的学习能力可以利用神经网络、贝叶斯技术或遗传算法得到。
非定性技术可以让 NPC 自己学习,并进化出新的行为,比如说突现行为(没有明确指示而出现的行为),让玩家在玩游戏时难以预测,增加游戏可玩性。开发者也无需事先预先所有可能的场景,写下所有明确的行为。
由于无法预测,就很难测试和调试,易出bug(开发者无法预测所有的玩家行动)。
现有的游戏AI技术
有限状态机
- 列举出计算机控制的角色的一连串动作或状态,再利用
if-then条件语句检查各类情况和满足条件,再根据判断结果执行动作或更新角色状态,或者在动作和状态之间做转换。
- 列举出计算机控制的角色的一连串动作或状态,再利用
模糊状态机
- 不太精确的条件设计规则
路径寻找技巧和A * 算法
人工生命系统
- 展现出符合人性的行为,突现行为。
几个主流游戏都用了非定性 AI 技术,比如“Creatures”、“Black & White”、“Battlecruiser 3000AD”、“Dirt Track Racing”、“Fields of Battle”以及“Heavy Gear”。这些游戏的成功,重新点燃了人们对“学习”AI 技术的兴趣,诸如决策树、神经网络、遗传算法以及概率方法。
追逐和闪躲
- 追或逃的决策判断(状态机/神经网络)
- 开始追或逃
- 避开障碍物
砖块环境/连续环境
连续环境里 基本追逐代码 if-else
根据猎物的坐标来修改追击者的坐标
移动模式
固定模式的移动:守卫的巡逻、宇宙飞船的降落
制造智能行为的幻觉
- 标准移动模式
- 编码过的指令清单或数组,指示计算机控制的角色,在每一轮循环如何移动。
double x - 事先定义出控制结构体类型的全局数组或者一组数组,以便存储模式数据。
Pattern[x].turnRight= Pattern[x].turnLeft= ...entityList[1].BuildPathSegment(x1,y1,a1,b1); entityList[1].BuildPathSegment(x2,y2,a2,b2); ...1
2
3
4
5
6
7
8x=1,2,3,4...
索引值递增
- 常见做法:编写好几个不同模式,存放在不同数组中,然后让计算机随机选取一个模式来使用,或者按照游戏中某些其他决策逻辑来决定。
- **砖块环境中的移动模式**
- 用相对坐标,每次初始坐标选为-1
- 建立起一个模式,比如在坐标(10,3)和(18,3)之间来回走动,此假如为巨人的巡逻状态,若感知到他人靠近则切换到追逐或攻击状态
- 参考像素rpg中怪物的巡逻,一个区域的怪物有固定的路线
- 复杂巡逻模式,例:一个由八条线段组成的模式
- 编码过的指令清单或数组,指示计算机控制的角色,在每一轮循环如何移动。
- 加入随机因素的移动模式
- 检查当前位置周围八个方向,发现其值为1时就把坐标储存到数组中,每个点都检查过后,可以从找到有效点的数组中,随机选取新的坐标点。
- 注意将之前的坐标排除在外
- 仿真物理环境中的移动模式
- 为物理引擎提供控制力信息,才能让计算机控制的载具,可以按照想要的模式实际运行。
- 每轮仿真运算时,物理引擎会处理这些指令,直到该组指令中指定的条件满足为止。此时,模式数组中的下一组指令就会被选出并执行。这个过程将一直重复,直到模式数组走完或者模式因某种原因而中断为止。
- 定义模式
- 方形模式/蛇形模式/任意形状的模式
- 执行模式
- 径度单位的角度,乘以180,除以pi,才会得到角度
群聚
A-life算法的实例
- 基本群聚算法的三个规则
- 凝聚:每个单位都往其邻近单位的平均位置行动。
- 对齐:每个单位行动时,都要把自己对齐在其邻近单位的平均方向上。
- 分割:每个单位行动时,要避免撞上其邻近单位。
从这三条语句可以得知,每个单位都必须有比如运用转向力行进的能力。此外,每个单位都必须得知其局部的周遭情况,必须知道邻近单位在哪里、它们的方向如何以及它们和自身有多接近。
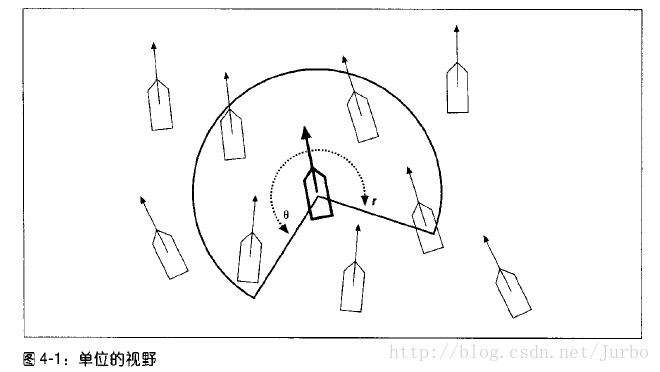
如图,弧半径r较大时会让单位看到群体中更多的伙伴,较小时会让群体分裂。
角度theta量定了每个单位的视野范围,决定了队伍的行进方式(一排蚂蚁或几排几列的军队)。
实例
仿真大约20个单位,以群聚的方式移动,避开圆形的物体,群聚中的诸多单位和玩家的互动就是去追玩家
行进模式
以物理机制为基础,把每个单位视为刚体,在单位前方施加转向力;控制好每条规则贡献的转向力,并调整行进模式,以确保每个单位都获得平衡
影响施加的力的两条规则:
避开规则
为了让单位不要彼此撞上,且根据对齐规则和凝聚规则而靠在一起,此规则贡献的转向力随距离的增大而减小。
对齐规则
考虑当前单位的当前方向,与其邻近单位间平均方向间的角度。转向力随角度增大而增大。
邻近单位
凝聚、对齐、分隔三个规则起作用的前提是侦测每个当前单位的邻近单位。邻近单位就是当前单位视野范围内的单位。
UpdateSimulation()函数,每次走过游戏循环或仿真运算循环时,就会被调用。更新每个单位的位置并把每个单位画到画面显示缓冲区内。DoUnitAI()函数处理一切和计算机控制单位的移动有关的事。所有群聚规则在此函数内实现。- 宽广视野
- 有限视野
- 狭窄视野
凝聚
凝聚指的是我们想让所有单位都待在同一个群体中,每个单位都应朝其邻近单位的平均位置前进。
邻近单位平均位置:各个位置的向量总和再除以总邻近单位数。
对齐
对齐的意思是指,我们想让群聚中的所有单位都大致朝相同方向前进。
每个单位在行进时,试着以等同于其邻近单位平均方向的方向来前进。
分隔
每个单位彼此间保持着最小距离,采用分隔手段,让每个单位和其视野内的邻近单位保持某一预定的最小分隔距离。此规则需要逐一检视每个邻近单位,而不是使用平均值。
避开障碍物
提供某种机制,使单位看得到前方的障碍物,再施加适当的转向力,使其能避开路径中的障碍物。
替单位安装虚拟触角,或者使用虚拟体积。
跟随领头者
群体移动更有目的性。
根据玩法决定是否有领头者(是否需要分散攻击)。决定领头者后,其他单位采用不同视野使不同队形排成(横、纵队)。
人人都可能是领头者。使用简单的规则,找出谁应该或足以担任领头者。